Difference Between Bagging and Random Forest
Over the years, multiple classifier systems, also called ensemble systems have been a popular research topic and enjoyed growing attention within the computational intelligence and machine learning community. It attracted the interest of scientists from several fields including Machine Learning, Statistics, Pattern Recognition, and Knowledge Discovery in Databases. Over time, the ensemble methods have proven themselves to be very effective and versatile in a broad spectrum of problem domains and real-world applications. Originally developed to reduce the variance in automated decision-making system, ensemble methods have since been used to address a variety of machine learning problems. We present an overview of the two most prominent ensemble algorithms – Bagging and Random Forest – and then discuss the differences between the two.
In many cases, bagging, that uses bootstrap sampling, classification tress have been shown to have higher accuracy than a single classification tree. Bagging is one of the oldest and simplest ensemble-based algorithms, which can be applied to tree-based algorithms to enhance the accuracy of the predictions. There’s yet another enhanced version of bagging called Random Forest algorithm, which is essentially an ensemble of decision trees trained with a bagging mechanism. Let’s see how the random forest algorithm works and how is it any different than bagging in ensemble models.
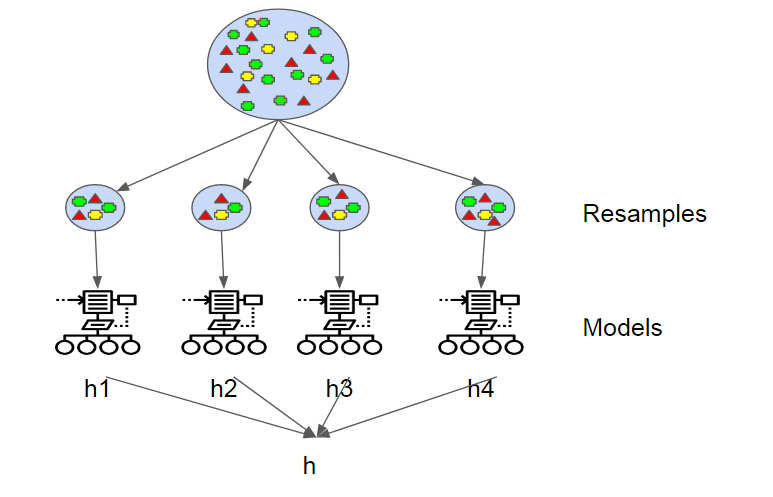
Bagging
Bootstrap aggregation, also known as bagging, is one of the earliest and simplest ensemble-based algorithms to make decision trees more robust and to achieve better performance. The concept behind bagging is to combine the predictions of several base learners to create a more accurate output. Leo Breiman introduced the bagging algorithm in 1994. He showed that bootstrap aggregation can bring desired results in unstable learning algorithms where small changes to the training data can cause large variations in the predictions. A bootstrap is a sample of a dataset with replacement and each sample is generated by sampling uniformly the m-sized training set until a new set with m instances is obtained.
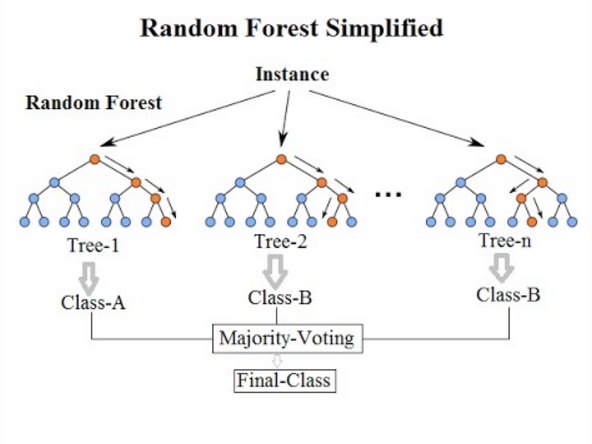
Random Forest
Random forest is a supervised machine learning algorithm based on ensemble learning and an evolution of Breiman’s original bagging algorithm. It’s a great improvement over bagged decision trees in order to build multiple decision trees and aggregate them to get an accurate result. Breiman added an additional random variation into the bagging procedure, creating greater diversity amongst the resulting models. Random forests differ from bagged trees by forcing the tree to use only a subset of its available predictors to split on in the growing phase. All the decision trees that make up a random forest are different because each tree is built on a different random subset of data. Because it minimizes overfitting, it tends to be more accurate than a single decision tree.
Difference between Bagging and Random Forest
Basics
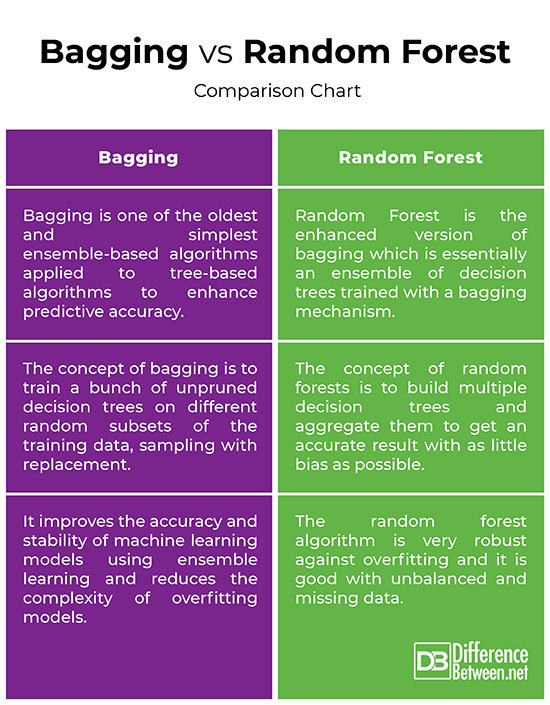
– Both bagging and random forests are ensemble-based algorithms that aim to reduce the complexity of models that overfit the training data. Bootstrap aggregation, also called bagging, is one of the oldest and powerful ensemble methods to prevent overfitting. It is a meta-technique that uses multiple classifiers to improve predictive accuracy. Bagging simply means drawing random samples out of the training sample for replacement in order to get an ensemble of different models. Random forest is a supervised machine learning algorithm based on ensemble learning and an evolution of Breiman’s original bagging algorithm.
Concept
– The concept of bootstrap sampling (bagging) is to train a bunch of unpruned decision trees on different random subsets of the training data, sampling with replacement, in order to reduce variance of decision trees. The idea is to combine the predictions of several base learners to create a more accurate output. With Random forests, an additional random variation is added into the bagging procedure in order to create greater diversity amongst the resulting models. The idea behind random forests is to build multiple decision trees and aggregate them to get an accurate result.
Goal
– Both bagged trees and random forests are the most common ensemble learning instruments used to address a variety of machine learning problems. Bootstrap sampling is a meta-algorithm designed to improve the accuracy and stability of machine learning models using ensemble learning and reduce the complexity of overfitting models. The random forest algorithm is very robust against overfitting and it is good with unbalanced and missing data. It is also the preferred choice of algorithm for building predictive models. The goal is to reduce the variance by averaging multiple deep decision trees, trained on different samples of the data.
Bagging vs. Random Forest: Comparison Chart
Summary
Both bagged trees and random forests are the most common ensemble learning instruments used to address a variety of machine learning problems. Bagging is one of the oldest and simplest ensemble-based algorithms, which can be applied to tree-based algorithms to enhance the accuracy of the predictions. Random Forests, on the other hand, is a supervised machine learning algorithm and an enhanced version of bootstrap sampling model used for both regression and classification problems. The idea behind random forest is to build multiple decision trees and aggregate them to get an accurate result. A random forest tends to be more accurate than a single decision tree because it minimizes overfitting.
- Difference Between Caucus and Primary - June 18, 2024
- Difference Between PPO and POS - May 30, 2024
- Difference Between RFID and NFC - May 28, 2024
Search DifferenceBetween.net :
Leave a Response
References :
[0]Image credit: https://commons.wikimedia.org/wiki/File:Random_forest_diagram_complete.png
[1]Image credit: https://commons.wikimedia.org/wiki/File:Bagging.png
[2]Zhou, Zhi-Hua. Ensemble Methods: Foundations and Algorithms. Boca Raton, Florida: CRC Press, 2012. Print
[3]Sarkar, Dipayan and Vijayalakshmi Natarajan. Ensemble Machine Learning Cookbook. Birmingham, UK: Packt Publishing, 2019. Print
[4]Finlay, Steven. Credit Scoring, Response Modeling, and Insurance Rating: A Practical Guide to Forecasting Consumer Behavior. Berlin, Germany: Springer, 2012. Print
[5]Fischetti, Tony, et al. R: Predictive Analysis. Birmingham, UK: Packt Publishing, 2017. Print
[6]Zhang, Cha and Yunqian Ma. Ensemble Machine Learning: Methods and Applications. Berlin, Germany: Springer, 2012. Print