Difference Between Data Mining Supervised and Unsupervised
Data mining makes use of a plethora of computational methods and algorithms to work on knowledge extraction. Classification is perhaps the most basic form of data analysis. A common task in data mining is to examine data where the classification is unknown or will occur in the future, with the goal to predict what that classification is or will be. Similarly, data where the classification is known are use to develop rules, which are then applied to the data where the classification is unknown. That being said, the techniques of data mining come in two main forms: supervised and unsupervised. Supervised is a predictive technique whereas unsupervised is a descriptive technique. Although both the algorithms are widely used to accomplish different data mining tasks, it is important to understand the difference between the two.

What is Supervised Data Mining?
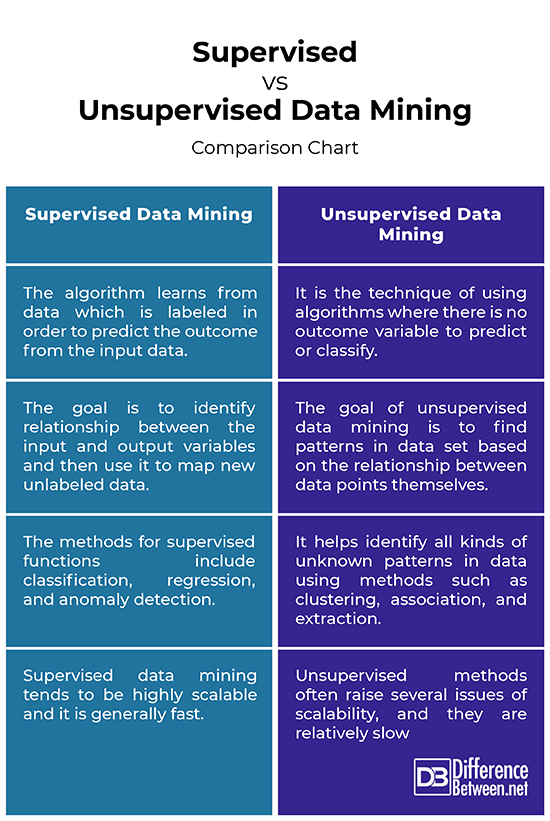
Supervised data mining, as the name suggests, refers to learning algorithms that are used in classification and prediction. Supervised algorithm learns from the training data which is labeled and the task is controlled by the knowledge engineer and system designer. With supervised data, we must have known inputs corresponding to known outputs, as determined by domain experts. The data mining task is often referred to as supervised learning because the classes are determined before examining the data. This technique uses an objective function (the dependent variable) and a set of data elements which are independent variables. Supervised technique attempts to identify relationships between dependent and independent variables, identify the degree of correlation for each set of variables, and build a model showing the web of dependencies. The model is then applied to the data for which the target value is unknown.

What is Unsupervised Data Mining?
Unlike supervised technique, unsupervised data mining does not have a predetermined objective function, nor does it predict a target value. Unsupervised techniques are those where there is no outcome variable to predict or classify. Hence, there is no learning from cases where such an outcome variable is known. The algorithm requires the user to specify the number of intervals and/or how many data points should be included in any given interval. It helps you identify all kinds of unknown patterns in data. Unsupervised model is also called descriptive model because it looks for unknown patterns in a data set with no predetermined labels and with no or minimal human supervision. Unsupervised learning methods include clustering, association, and extraction methods. This type of learning technique is used when a specific goal is not available or when the user seeks to find hidden relationships in data.
Difference between Data Mining Supervised and Unsupervised
Data
– Supervised learning is the data mining task of using algorithms to develop a model on known input and output data, meaning the algorithm learns from data which is labeled in order to predict the outcome from the input data. Supervised technique is simply learning from the training data set. Unsupervised learning, on the other hand, is the technique of using algorithms where there is no outcome variable to predict or classify, meaning there is no learning from cases where such an outcome variable is known.
Goal
– Supervised technique attempts to identify casual relationships between dependent and independent variables, isolate the degree of correlation for each set of variables, and develop a model showing the web of dependencies. The model is then applied to data for which the target value is unknown. Unsupervised learning seeks to identify unknown patterns in a data set with no predetermined labels and with no or minimal human supervision. The goal of unsupervised data mining techniques is to find patterns in data set based on the relationship between data points themselves.
Method
– Supervised models are those used in classification and prediction, hence called predictive models because they learn from the training data, which is the data from which the classification or the prediction algorithm learns. Once the algorithm has learned from the training data, it is then applied to another sample of data where the outcome is known. The methods include the following supervised functions: classification, regression, and anomaly detection. Unsupervised data mining helps you identify all kinds of unknown patterns in data using methods such as clustering, association, and extraction.
Scalability
– Scalability is one of the major issues with mining large data sets and it is not practical to parse the entire data set more than once. Supervised data mining tends to be highly scalable, meaning it can handle huge volumes of data in time frames that do not increase unreasonably, and it is generally fast. Unsupervised learning methods, on the other hand, often raise several issues when it comes to scalability if some sort of parallel evaluation is not used, and unlike supervised learning, it is relatively slow, but it can converge toward multiple sets of solution states.
Supervised vs. Unsupervised Data Mining: Comparison Chart
Summary
In a nutshell, supervised data mining is a predictive technique whereas unsupervised data mining is a descriptive technique. Supervised techniques are used when a definite goal is available and the user seeks to determine how the changes in the state of the data influence the outcome. Unsupervised data mining, on the other hand, starts with a clean slate, meaning it has no predefined objective function and the user attempts to find unknown patterns or hidden relationships in the data. The goal of unsupervised data mining is to find patterns in data set based on the relationship between data points themselves.
- Difference Between Caucus and Primary - June 18, 2024
- Difference Between PPO and POS - May 30, 2024
- Difference Between RFID and NFC - May 28, 2024
Search DifferenceBetween.net :
Leave a Response
References :
[0]Shmueli, Galit et al. Data Mining for Business Intelligence: Concepts, Techniques, and Applications in Microsoft Office Excel with XLMiner. Hoboken, New Jersey: John Wily & Sons, 2011. Print
[1]Shmueli, Galit et al. Data Mining for Business Intelligence: Concepts, Techniques, and Applications in Microsoft Office Excel with XLMiner. Hoboken, New Jersey: John Wily & Sons, 2011. Print
[2]Cox, Earl. Fuzzy Modeling and Genetic Algorithms for Data Mining and Exploration. Cambridge, Massachusetts: Academic Press, 2005. Print
[3]Cios, Krzysztof J. et al. Data Mining: A Knowledge Discovery Approach. Berlin, Germany: Springer, 2007. Print
[4]Image credit: https://upload.wikimedia.org/wikipedia/commons/thumb/b/b2/Data_Mining.svg/1280px-Data_Mining.svg.png
[5]Image credit: https://live.staticflickr.com/7267/7714852924_a2dc7c3c9d_b.jpg