Difference Between Tokenization and Masking
One of the biggest concerns of organizations dealing with banking, insurance, retail, and manufacturing is data privacy because these companies collect large amounts of data about their customers. And these are not just any data but sensitive, private data, which when mined properly gives a lot of insights about their customers. Companies use these data about customers to make better business decisions like providing value-added services to customers, which may result in added revenue and increased profit. All these are sensitive data which must be protected at all times as they could be exploited if they fall into the wrong hands. This brings us to our topic of interest – data privacy. When it comes to data privacy, there are two common yet effective methods available to protect sensitive data – tokenization and masking.
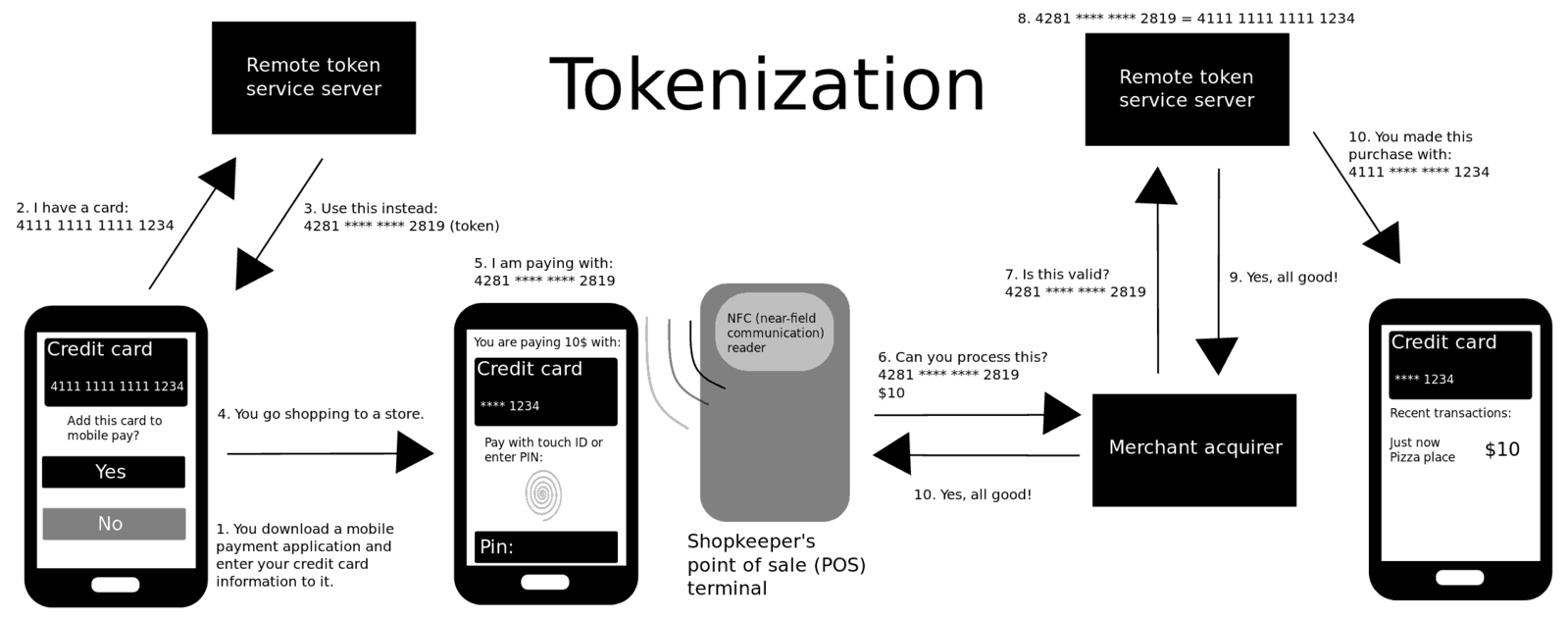
What is Tokenization?
Tokenization is probably one of the oldest techniques used to keep your data secure. Because most of your data and information is online, such as digital wallets, it is essential to keep your data protected from prying eyes. Tokenization is a method of substituting the original sensitive data with non-sensitive placeholders referred to as tokens. The idea is to completely replace the original data with a surrogate that has no relation to the original data. The tokenization technique is extensively used in the credit card industry but over time, it’s being adopted by other domains as well. What it actually does is keep your sensitive data such as your credit card number in something called a token vault, which basically sits outside the system in a secure location. Although, the token is associated with your secure data, it is completely useless elsewhere. It is merely a reference to your sensitive data and that’s it.

What is Masking?
Masking is yet another effective solution to protecting the privacy of data. As you know, the volume of data that organizations have to manage is growing at an unprecedented rate. And protecting the privacy of data becomes a new challenge. Masking is a technique used to protect the privacy of desensitized data for the production and testing environment. It is a process of obscuring, anonymizing, or suppressing data by replacing sensitive data with random characters or just any non-sensitive data. It basically protects your sensitive data from being exposed to individuals who are not authorized to view or access it. Masking allows developers to access secure databases without risking exposure to sensitive information. There are several techniques used for data masking such as substitution, scrambling or deletion. Masking is often used to protect credit card numbers and other sensitive financial information.
Difference between Tokenization and Masking
Technique
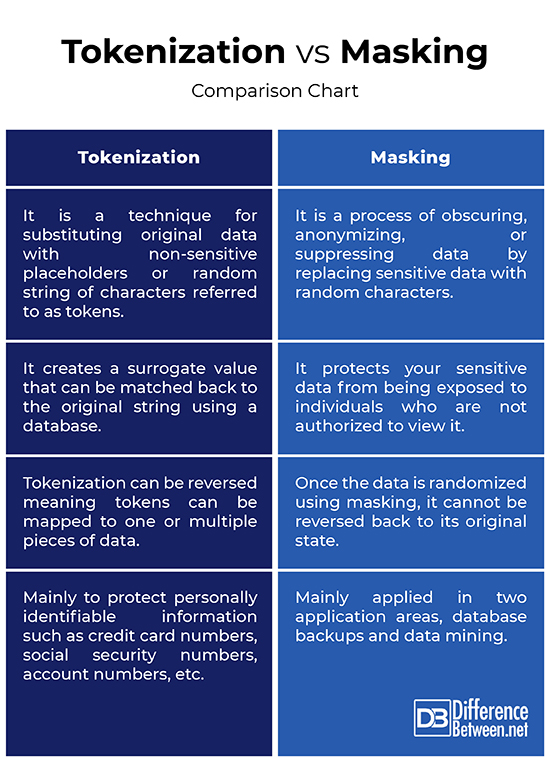
– While both tokenization and masking are great techniques used to protect sensitive data, tokenization is mainly used to protect data at rest whereas masking is used to protect data in use. Tokenization is a technique for substituting original data with non-sensitive placeholders referred to as tokens. The token has no meaning outside the system that creates them and links them to other data. The idea behind data masking is similar but it is essentially referred to as permanent tokenization. Masking is hiding the original sensitive data by replacing it with random characters.
Process
– Tokenization takes a value such as a customer’s credit card number and replaces it with a series of randomly generated numbers called tokens. This is where you cannot get back to the original value because it conveniently sits outside the system in a secure location. The idea is to create a surrogate value that can be matched back to the original string using a database. Unlike tokenization, masking cannot be reversed meaning once the data is randomized using a masking process, it cannot be reversed back to its original state.
Use Cases
– The most common use of tokenization is to protect sensitive or personally identifiable information such as credit card numbers, social security numbers, account numbers, email addresses, telephone numbers, passport numbers, driving license number, and so on. Data masking, in practice, is mainly applied in two application areas, database backups and data mining. Masking could be ideal when you need to mock data without having seen the original data. This could be beneficial for testing or profiling purposes. There are several techniques used for data masking such as substitution, scrambling, shuffling, encryption, or deletion.
Tokenization vs. Masking: Comparison Chart
Summary
Both are commonly used techniques applied as part of a comprehensive data privacy strategy but simply knowing about them is not enough a build an effective security architecture. As one of the fundamental data privacy strategies in existence, tokenization is one of the most common methods used to de-identify sensitive information by substituting the original data with a non-sensitive value called a token. This token is merely a reference to the original data, but it has no value of its own. It only looks like the original data and is mapped back to the original data using a database. The idea behind data masking is similar, but the difference lies in how they work. Masking basically suppresses the data by replacing it with random characters or just any non-sensitive data, and it can be done by one of many ways.
- Difference Between Caucus and Primary - June 18, 2024
- Difference Between PPO and POS - May 30, 2024
- Difference Between RFID and NFC - May 28, 2024
Search DifferenceBetween.net :
Leave a Response
References :
[0]Deane. CCSP For Dummies with Online Practice. New Jersey, United States: John Wiley & Sons, 2020. Print
[1]Venkataramanan, Nataraj and Ashwin Shriram. Data Privacy: Principles and Practice. Florida, United States: CRC Press, 2016. Print
[2]Godinez, Mario et al. The Art of Enterprise Information Architecture: A Systems-Based Approach for Unlocking Business Insight. London, United Kingdom: Pearson Education, 2010. Print
[3]Chapple, Mike et al. (ISC)2 CISSP Certified Information Systems Security Professional Official Study Guide. New Jersey, United States: John Wiley & Sons, 2018. Print
[4]Image credit: https://upload.wikimedia.org/wikipedia/commons/thumb/4/49/QR_Code_Masking_Example.svg/500px-QR_Code_Masking_Example.svg.png
[5]Image credit: https://commons.wikimedia.org/wiki/File:How_mobile_payment_tokenization_works.png