Difference Between Hadoop and Spark
One of the biggest problems with respect to Big Data is that a significant amount of time is spent on analyzing data that includes identifying, cleansing and integrating data. The large volumes of data and the requirement of analyzing the data lead to data science. But often the data is scattered across many business applications and systems which make them a little hard to analyze. So, the data needs to be reengineered and reformatted to make it easier to analyze. This requires more sophisticated solutions to make information more accessible to users. Apache Hadoop is one such solution used for storing and processing big data, along with a host of other big data tools including Apache Spark. But which one’s the right framework for data processing and analyzing – Hadoop or Spark? Let’s find out.
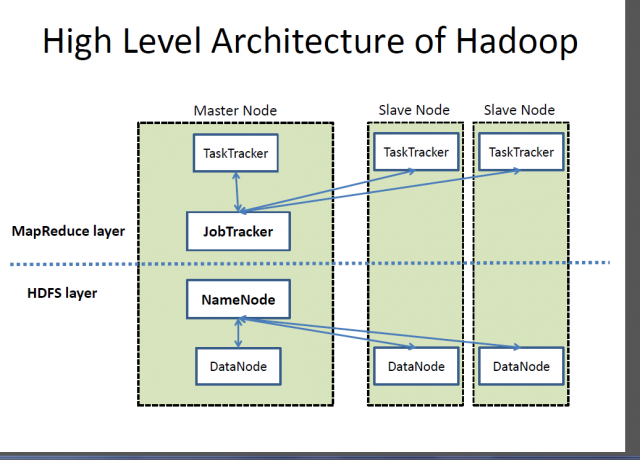
Apache Hadoop
Hadoop is a registered trademark of Apache Software Foundation and an open-source framework designed for storing and processing very large data sets across clusters of computers. It handles very large scale data at reasonable cost in a reasonable time. In addition, it also provides mechanisms to improve computation performance at scale. Hadoop provides a computational framework to store and process Big Data using the Google’s MapReduce programming model. It can work with single server or can scale up including thousands of commodity machines. Although, Hadoop was developed as part of an open-source project within the Apache Software Foundation based on MapReduce paradigm, today there are a variety of distributions for Hadoop. However, MapReduce is still an important method used for aggregation and counting. The basic idea on which MapReduce is based is parallel data processing.
Apache Spark
Apache Spark is an open-source cluster computing engine and a set of libraries for large-scale data processing on computer clusters. Built on top of the Hadoop MapReduce model, Spark is the most actively developed open-source engine to make data analysis faster and make programs run faster. It enables real-time and advanced analytics on the Apache Hadoop platform. The core of Spark is a computing engine consisting of scheduling, distributing and monitoring applications that are composed of many computing tasks. Its key driving goal is to offer a unified platform for writing Big Data applications. Spark was originally born at the APM laboratory at the University of Berkeley and now it is one of the top open-source projects under the portfolio of Apache Software Foundation. Its unparalleled in-memory computing capabilities enable analytic applications to run up to 100 times faster on Apache Spark than other similar technologies on the market today.
Difference between Hadoop and Spark
Framework
– Hadoop is a registered trademark of Apache Software Foundation and an open-source framework designed for storing and processing very large data sets across clusters of computers. Basically, it’s a data processing engine that handles very large scale data at reasonable cost in a reasonable time. Apache Spark is an open-source cluster computing engine built on top of the Hadoop’s MapReduce model for large scale data processing and analyzing on computer clusters. Spark enables real-time and advanced analytics on the Apache Hadoop platform to speed up the Hadoop computing process.
Performance
– Hadoop is written in Java so it requires writing long lines of code which takes more time for the execution of program. The originally developed Hadoop MapReduce implementation was innovative but also fairly limited and also not very flexible. Apache Spark, on the other hand, is written in a concise, elegant Scala language to make the programs run easier and faster. In fact, it is able to run applications up to 100 times faster than not only Hadoop but also other similar technologies on the market.
Ease of Use
– Hadoop MapReduce paradigm is innovative but fairly limited and inflexible. MapReduce programs are run in batch and they are useful for aggregation and counting at large scale. Spark, on the other hand, provides consistent, composable APIs that can be used to build an application out of smaller pieces or out of existing libraries. Spark’s APIs are also designed to enable high performance by optimizing across the different libraries and functions composed together in a user program. And since Spark caches most of the input data in memory, thanks to RDD (Resilient Distributed Dataset), it eliminates the need to load multiple times into memory and disk storage.
Cost
– The Hadoop File System (HDFS) is a cost effective way to store large volumes of data both structured and unstructured in one place for deep analysis. Hadoop’s cost per terabyte is much less than the cost of other data management technologies that are used widely to maintain enterprise data warehouses. Spark, on the other hand, is not exactly a better option when it comes to cost efficiency because it requires a lot of RAM to cache data in memory, which increases the cluster, hence the cost marginally, compared to Hadoop.
Hadoop Vs. Spark: Comparison Chart

Summary of Hadoop vs. Spark
Hadoop is not only an ideal alternative to store large amounts of structured and unstructured data in a cost effective way, it also provides mechanisms to improve computation performance at scale. Although, it was originally developed as an open source Apache Software Foundation project based on Google’s MapReduce model, there are a variety of different distributions available for Hadoop today. Apache Spark was built on top of the MapReduce model to extend its efficiency to use more types of computations including Stream Processing and Interactive Queries. Spark enables real-time and advanced analytics on the Apache Hadoop platform to speed up the Hadoop computing process.
- Difference Between Caucus and Primary - June 18, 2024
- Difference Between PPO and POS - May 30, 2024
- Difference Between RFID and NFC - May 28, 2024
Search DifferenceBetween.net :
Leave a Response
References :
[0]Image credit: https://commons.wikimedia.org/wiki/File:Sch%C3%A9ma_d%C3%A9tail_outils_spark.png
[1]Image credit: https://commons.wikimedia.org/wiki/File:Hadoop-HighLevel_hadoop_architecture-640x460.png
[2]Dunning, Ted and Ellen Friedman. Real-World Hadoop. Sebastopol, California: O’Reilly Media, 2015. Print
[3]Chambers, Bill and Matei Zaharia. Spark: The Definitive Guide. Sebastopol, California: O’Reilly Media, 2018. Print
[4]Revathi, T., et al. Big Data Processing with Hadoop. Pennsylvania, United States: IGI Global, 2018. Print