Difference Between Hadoop and SQL
The term ‘Big Data’ is one of the hottest buzzwords in today’s digital era. Every company ranging from small startups to the large enterprises has money for Big Data. Suddenly we are seeing the convergence of significant trends that are fundamentally transforming the industry and there is an explosion of data because of the increasing number of Internet-connected devices. Big Data is exactly where the open-source framework Hadoop comes to the picture. Hadoop provides a framework for storing and retrieving huge amounts of data for processing and analytical purposes. But how Hadoop is any different than other database management systems such as the SQL Server? We highlight some key differences between SQL and Hadoop.
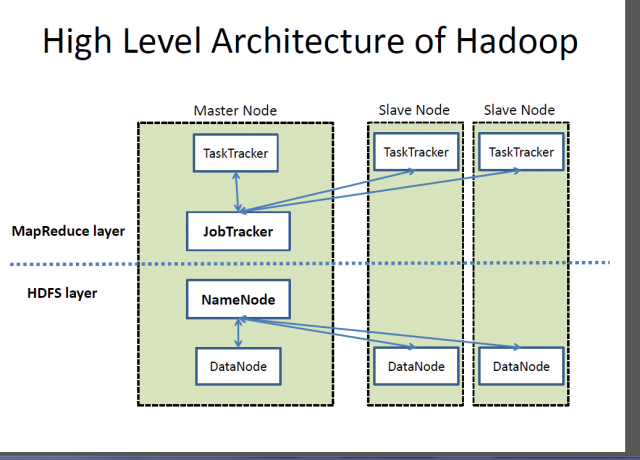
What is Hadoop?
Hadoop is an open-source distributed processing framework designed to meet the needs of web companies to index and process massive volumes of data, courtesy of the increasing rise of Internet enabled devices and the next big evolution called social media. Google provides the inspiration for the development that became known as Hadoop. It provides a framework that allows for processing of massive volumes of data in order to provide easy access and to load data dynamically.
What is SQL?
SQL has been the ubiquitous tool to access and manipulate data in a database. SQ Server is no more a regular database management system used by developers and database administrators and analysts. It is a huge ecosystem of difference tools and services that work in conjunction to provide very complex data platform management tasks. It is the de facto language for transactional and decision support systems and Business Intelligence tools to access ad query a variety of data sources. In fact, SQL Server handles enforcing data quality and consistency much better than Hadoop.
Difference between Hadoop and SQL
Tool
– Hadoop is an Apache Software Foundation project and an open-source distributed processing software framework for storing and processing massive influx of data and running applications on clusters of commodity hardware. Hadoop provides a framework that allows for processing of massive volumes of data in order to provide easy access and to load data dynamically. SQL, short for Structured Query Language, on the other hand, is the de facto language for transactional and decision support systems and Business Intelligence tools to access and query a variety of data from different sources. SQL has been the ubiquitous tool to access, manipulate and store data in a database.
Framework of Hadoop vs. SQL
– At the core of the Hadoop ecosystem are two primary components – the Hadoop Distributed File System (HDFS) – a distributed, scalable and portable file system written in Java to store very large data sets across clusters of computers; and an approach to distributed processing based on Java called MapReduce. SQL Server, on the other hand, is a relational database management system and one of the world’s most powerful data platforms used by a number of commercial and in-house products to query, manipulate and visualize a variety of data sources.
Data Type
– Hadoop is designed to work with any data type, whether it is structured, semi-structured or unstructured, making it very flexible to work with when it comes to big data processing. SQL, on the other hand, is a programming language specifically created for managing and querying data in relational database management systems (RDBMS). It is based on the Entity- Relationship model of the RDBMS, so it can only process structured data. SQL cannot be used for unstructured data because they do not conform to a data model with no easily identifiable structure.
Processing
– The HDFS is a distributed file system designed to support batch processing of data meaning data is collected in batches and each batch is sent for processing. The batch can be anything from one day to one minute. Since it’s designed for batch processing, it does not have the concept of random reads or writes. SQL Server, on the contrary, as a general-purpose database platform, supports real-time data processing, meaning data is streamed from the sender to the receiver as soon as it is produced at the source end.
Performance of Hadoop and SQL
– The architecture of Hadoop sometimes leads to an impedance mismatch between data storage and data access. It has fewer restrictions or validations on the data it stores, and it does not have the same end-user capabilities and ecosystem that SQL has developed. SQL Server, on the other hand, handles enforcing data quality and consistency much better than Hadoop which enables it to leverage the ecosystem of SQL based data analysis and data visualization tools. However, SQL has some drawbacks too which includes scalability to handle massive amounts of data and support for storing loosely formatted data.
Hadoop vs. SQL: Comparison Chart

Summary of Hadoop vs. SQL
Hadoop is the most preferred and widely accepted Big Data tool designed to work with any data type – structured, unstructured or semi-structured. But when it comes to RDBMS, SQL is perhaps the most powerful, in-memory and dynamic data storage and management system. However, existing RDBMS solutions such as SQL Servers are only for managing significant volume of data, but not for unstructured or semi-structured data with variable attributes. As with many platforms, Hadoop and SQL Server both have its fair share of strengths and weaknesses. Use both of them together and you can leverage the strengths of each while mitigating the weaknesses.
- Difference Between Caucus and Primary - June 18, 2024
- Difference Between PPO and POS - May 30, 2024
- Difference Between RFID and NFC - May 28, 2024
Search DifferenceBetween.net :
Leave a Response
References :
[0]Image credit: https://commons.wikimedia.org/wiki/File:Sql_developer_main_window.png
[1]Image credit: https://commons.wikimedia.org/wiki/File:Hadoop-HighLevel_hadoop_architecture-640x460.png
[2]Jorgensen, Adam, et al. Microsoft Big Data Solutions. Hoboken, New Jersey: John Wiley & Sons, 2014. Print
[3]Pal, Sumit. SQL on Big Data: Technology, Architecture, and Innovation. New York, United States: Apress, 2016. Print
[4]Sarkar, Debarchan. Microsoft SQL Server 2012 with Hadoop. Birmingham, United Kingdom: Packt Publishing, 2013. Print
[5]Turkington, Garry and Gabriele Modena. Learning Hadoop 2. Birmingham, United Kingdom: Packt Publishing, 2015. Print