Difference Between HBase and Hive
HBase and Hive are both Hadoop based data warehouse structures that differ significantly as to how they store and query data. Managing and processing huge volumes of web-based data are becoming increasingly difficult via conventional database management tools. This is where HBase comes to the picture. HBase is a preferred choice to handle large amounts of data. For example, if you need to filter through a huge store of emails to pull out one for auditing or for any other purpose, this will be a perfect use case for HBase. Hive, on the other hand, is more like a traditional data warehouse reporting system that runs on top of Hadoop. Hive offers an SQL-like query language that allows you to query the semi-structured data stored in Hadoop. This takes the unnecessary effort of having to write MapReduce code. Although, both HBase and Hive are used as data stores to store unstructured data, they are different.
What is Hbase?
HBase is an open-source, non-relational, database management system inspired by the Google’s Big Table architecture and written in Java. HBase is fundamentally a column-oriented, distributed NoSQL database that runs on top of the Hadoop Distributed File System (HDFS). It is designed and developed by many engineers under the framework of Apache Software Foundation. It sits on Apache Hadoop and powered by a fault-tolerant distributed file structure known as the HDFS. It provides a way to store sparse data sets, which are common in big data use cases. It allows quick reads of random access data from large amounts of data based on the key values. However, it is not designed to perform aggregations of the data.

What is Hive?
Hive is not exactly a database but a data warehousing package built atop Hadoop. Hive is a different technology than HBase; it structures the data in a set of tables that can be joined, aggregated and queried upon using a query language called Hive Query Language (HQL) that is very similar to the SQL, used for batch processing of big data. It allows you to query the semi-structured data stored in Hadoop, which is eventually turned into a MapReduce job, executed either locally or on a distributed MapReduce cluster. Hive is basically a data warehouse system for Hadoop that facilitates easy data summarization, ad-hoc queries, and the analysis of large data sets stored in Hadoop compatible file systems. Data can be read and written from Hive and HBase and vice-versa. However, it cannot be used for real time processing of data.
Difference between HBase and Hive
Technology
– Although HBase and Hive are both Hadoop based data warehouse structures used to store and process large amounts of data, they differ significantly as to how they store and query data. HBase is fundamentally a column-oriented, distributed NoSQL database that runs on top of the Hadoop Distributed File System (HDFS) and provides a fault-tolerant way to store sparse data sets, which are common in big data use cases. Hive, on the other hand, is not exactly a database but a data warehousing package built atop Hadoop. Hive is more like a traditional data warehousing reporting system.
Architecture
– HBase is a NoSQL database and an open-source implementation of the Google’s Big Table architecture that sits on Apache Hadoop and powered by a fault-tolerant distributed file structure known as the HDFS. It is a scalable storage solution to accommodate a virtually endless amount of data. It is a data storage architecture used for storing unstructured data. Hive, on the other hand, is an SQL engine built on top of HDFS and leverages MapReduce internally, allowing querying of data stored on HDFS via an SQL-like query language called HQL (Hive Query Language).
Use
– HBase is used to build a low-cost, flexible, and easy to maintain tile layer services – Hadoop based geographical information system (HBGIS) – in order for massive data storage. It is an on-disk column storage format that provides a way to store sparse data sets, which are common in big data use cases. It allows quick reads of random access data from large amounts of data based on the key values. Hive, on the other hand, is a standard for SQL queries over petabytes of data in Hadoop and provides a SQL-like query language called HQL for querying data stored in a Hadoop cluster.
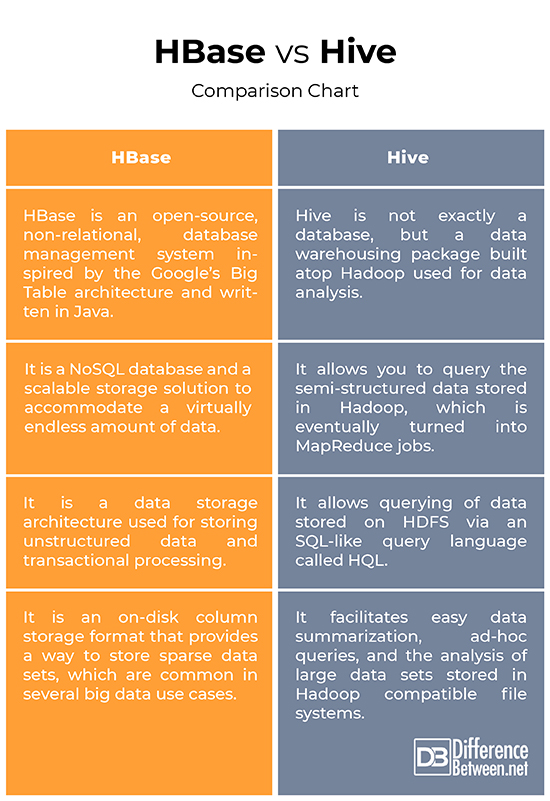
HBase vs. Hive: Comparison Chart
Summary
Although HBase and Hive are both Hadoop based data warehouse structures used to store and process large amounts of data, they differ significantly as to how they store and query data. HBase is a column-oriented database management system used for massive data storage and provides a way to store sparse data sets, which are common in several big data use cases. Hive, on the other hand, is more like a traditional data warehouse reporting system built atop Hadoop used to run processing through schedules jobs and then load the results into a summary type table that can be further queried on by client applications.
- Difference Between Caucus and Primary - June 18, 2024
- Difference Between PPO and POS - May 30, 2024
- Difference Between RFID and NFC - May 28, 2024
Search DifferenceBetween.net :
Leave a Response
References :
[0]Image credit: https://commons.wikimedia.org/wiki/File:Diagram_of_Lambda_Architecture_(named_components).png
[1]Image credit: https://live.staticflickr.com/8003/7550578346_e92226351b_b.jpg
[2]Jorgensen, Adam, et al. Microsoft Big Data Solutions. Hoboken, New Jersey: John Wiley & Sons, 2014. Print
[3]Abraham, Ajith. Emerging Technologies in Data Mining and Information Security (Volume 2). Berlin, Germany: Springer, 2018. Print
[4]George, Lars. HBase: The Definitive Guide. Sebastopol, California: O'Reilly Media, 2011. Print
[5]Capriolo, Edward, et al. Programming Hive. Sebastopol, California: O'Reilly Media, 2012. Print
[6]Pal, Sumit. SQL on Big Data: Technology, Architecture, and Innovation. New York, United States: Apress, 2016. Print